
Relevant Products
Scan workflows are available in BREEZE MFD pro mfp
Processing steps can transform (e.g., process images into a searchable PDF) or extract data from scanned documents into variables. Each of the processing steps can be enabled and configured independently.
You may enable or disable all the available processing steps in any workflow.
Barcode processing step
Enable this processing step to find barcodes of the selected barcode type.
Barcode type
Determines which barcode type should be identified and extracted from a document. The supported types are:
-
UPC A
-
UPC E
-
EAN 8
-
EAN 13
-
Code 39
-
Code 93
-
Code 128
-
Codabar
-
ITF
-
RSS 14
-
RSS Expanded
-
Any 1D barcode – the barcode in a document can be any of the supported (above-listed) 1D barcode types.
-
Aztec
-
Data Matrix
-
Maxicode
-
PDF 417
-
QR Code
Barcode variables
First occurrence of the barcode – The barcode step reads the barcode value and saves it into the {{barcode}} variable. If multiple barcodes of the selected type are found, the leftmost and uppermost barcode value is used. If no barcode is found, the {{barcode}} variable is set to an empty string.
-
-
Special characters "/\<>:"|?*~#%{}&" are removed to prevent unsafe user input.
-
Example:
-
{{barcode}} = ABCD1234
-
-
Multiple barcodes – Variables {{barcode<X>}} contain each barcode value with X starting from 1. If multiple barcodes are found, they are sorted from upper-left to bottom-right.
-
-
Special characters "/\<>:"|?*~#%{}&" are removed to prevent unsafe user input.
-
Example:
-
{{barcode1}} = ABCD1234
-
{{barcode2}} = C--TEMP
-
-
Non-sanitized multiple barcodes – Variables {{barcodeInsecure<X>}} contain each unmodified barcode value with X starting from 1. If multiple barcodes are found, they are sorted from upper-left to bottom-right.
-
-
The value may contain unsafe user input.
-
Example:
-
{{barcodeInsecure1}} = ABCD1234
-
{{barcodeInsecure2}} = C:\TEMP
-
-
JSON variables – Variables {{barcode_<JSON key path>}} contain barcode JSON values with a key path using dot notation replaced by an underscore character.
-
-
Special characters "/\<>:"|?*~#%{}&" are removed to prevent unsafe user input.
-
Example:
-
{{barcode_store_book_0_title}} = My Book
-
{{barcode_store_book_0_price}} = $10.00
-
-
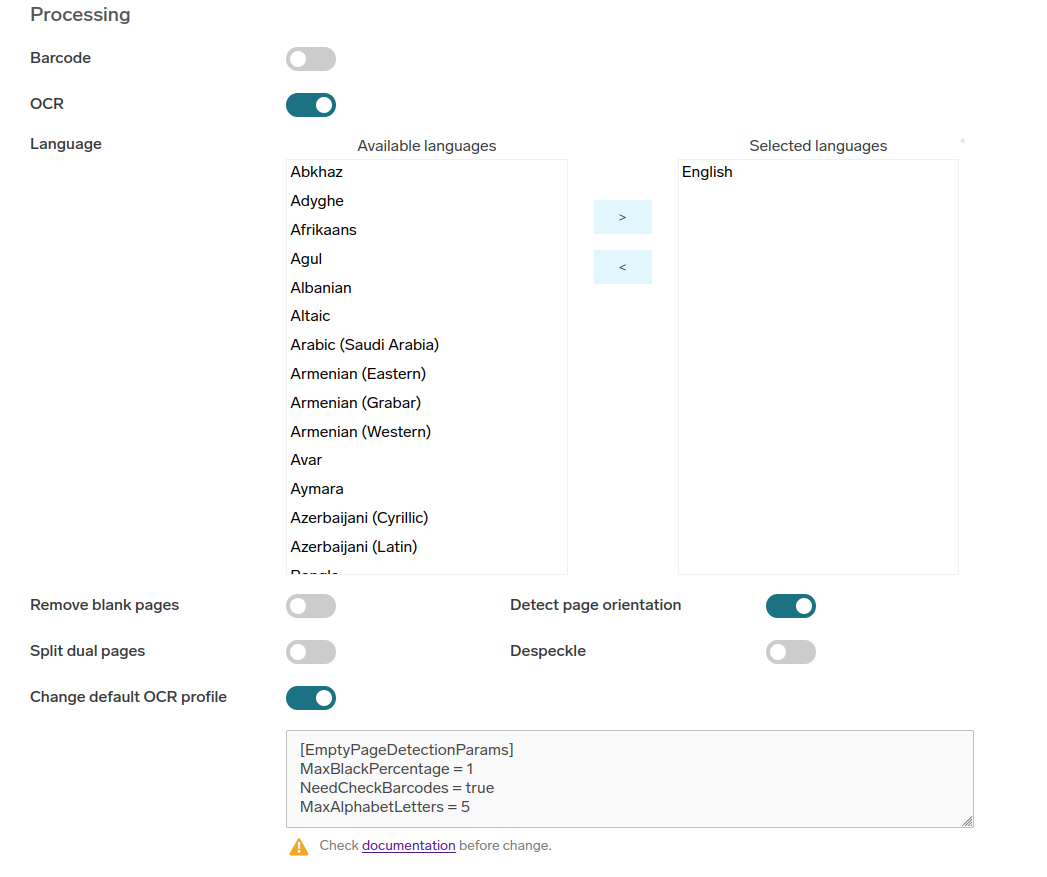
OCR processing step
Enable the OCR processing step to analyze text documents, recognize and extract document text and formatting, and save the result to a file of a selected output format. The OCR step recognizes only the common typographic type of text.
-
Language – Document languages. OCR processing requires the language setting to recognize the document's text correctly. You can select multiple languages.
See the Supported Languages section for the list of languages recognized by the OCR processing step.
The accuracy of OCR depends on many factors, such as the quality of the printed document, scanner quality, and text size. Therefore, it is never 100%, even with correctly configured document language. To get the best results out of OCR, we recommend you to use the following scan resolution settings:
-
For regular texts (font size 8-10 points), use 300 dpi resolution for OCR (in most cases, represented by the "Fine" setting) as the OCR technologies are tuned for that resolution.
-
For smaller font text sizes (8 points or smaller), use 400-600 dpi resolution.
-
Low image quality (e.g., low resolution) may decrease quality and speed as uncertainty in the character picture produces more recognition variants to process.
-
-
Remove blank pages – removes blank pages from the scanned document. The blank page detection algorithm is heuristic. Therefore, its results cannot always be accurate. There are predefined thresholds used for blank page detection. The page is not considered blank when any value of the following criteria is exceeded:
-
The maximum number of letters belonging to the recognition languages is five.
-
The maximum percentage of black areas on a page is one.
-
The maximum number of objects found on a page is 20.
-
If a page contains a barcode, it is not considered blank.
If all pages in a scan job are evaluated as blank, the job will be processed without the option to remove them. Therefore all scanned pages will be included in the resulting document.
-
-
Detect page orientation – detects each page's orientation in the document and rotates upside-down pages to correct the orientation.
-
Split dual images – splits dual pages (e.g., when scanning double pages of a book) into two pages in the resulting document.
-
Despeckle – cleans the noise in the scanned document. This may impact the speed and performance of the OCR engine.
-
Change default OCR profile – allows customization of advanced OCR engine parameters using ABBYY FineReader Engine profile syntax. When enabled, custom processing parameters can be specified in INI format to fine-tune OCR behavior beyond the standard options.
The profile uses ABBYY's configuration format. Common use cases include:
Empty Page Detection Parameters:
MaxBlackPercentage– maximum percentage of black pixels for a page to be considered empty (-1 to disable, 0-100)
NeedCheckBarcodes– check for barcodes before marking a page as empty (true/false)
MaxAlphabetLetters– maximum alphabet letters allowed on an empty page (-1 to disable, 0-100)
MaxTextObjects– maximum text objects for a page to be considered empty (-1 to disable, 0-100)
Example configuration:[EmptyPageDetectionParams] MaxBlackPercentage = 2 NeedCheckBarcodes = true MaxAlphabetLetters = 10 MaxTextObjects = 15For more advanced configurations including page preprocessing and analysis parameters, refer to the ABBYY FineReader Engine documentation.
Modifying the OCR profile requires knowledge of OCR Engine parameters. Incorrect values may impact OCR accuracy or performance.
-
Scan Separation – split a batch scan into multiple documents. Scan jobs may be separated as follows.
See Scan separation processing step section for the step description
-
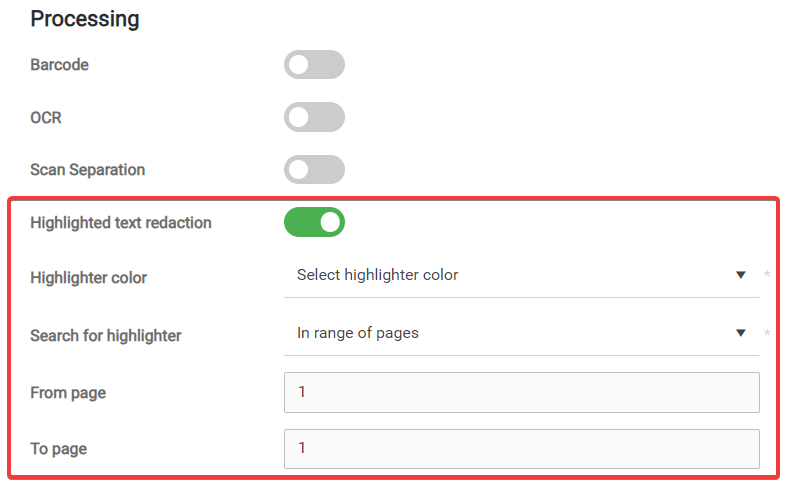
Highlighted text redaction - use the highlighter redaction step to redact (overlay with black) areas in a scanned document marked with the given color.
See Highlighter redaction processing step section for the step description
Supported languages
The OCR processing step supports the recognition of the following OCR languages:
-
Languages with dictionary support
-
Latin, Cyrillic, Greek or Armenian characters, for which the FineReader Engine provides dictionary support: Armenian (Eastern, Western, Grabar), Bashkir, Bulgarian, Catalan, Croatian, Czech, Danish, Dutch (Netherlands and Belgium), English, Estonian, Finnish, French, German (new and old spelling), Greek, Hungarian, Italian, Indonesian, Latvian, Lithuanian, Norwegian (Nynorsk and Bokmal), Polish, Portuguese (Portugal and Brazil), Romanian, Russian, Slovak, Slovenian, Spanish, Swedish, Tatar, Turkish, and Ukrainian.
-
Japanese, Korean, and Hangul with dictionary support, Chinese (PRC and Taiwan).
-
Japanese Modern (Japanese texts which may include Latin or Greek letters)
-
Thai with dictionary support.
-
Hebrew with dictionary support, Yiddish.
-
Arabic with dictionary support, Farsi.
-
Latin, Azerbaijani (Latin), and Russian (old spelling) with dictionary support.
-
-
Additional languages
-
Latin, Cyrillic, or Greek characters: Abkhaz, Adyghian, Afrikaans, Agul, Albanian, Altaic, Avar, Aymara, Azerbaijani (Cyrillic), Azerbaijani (Latin), Bangla, Basque, Belarusian, Bemba, Blackfoot, Breton, Bugotu, Burmese, Buryat, Cebuano, Chamorro, Chechen, Chukchee, Chuvash, Congo, Corsican, Crimean Tatar, Crow, Dakota, Dargwa, Dungan, Eskimo (Cyrillic), Eskimo (Latin), Even, Evenki, Faeroese, Fijian, Frisian, Friulian, Gagauz, Galician, Ganda, Georgian, German (Luxemburg), Guarani, Hani, Hausa, Hawaiian, Icelandic, Ingush, Irish, Jingpo, Kabardian, Kalmyk, Karachay-balkar, Karakalpak, Kasub, Kawa, Kazakh, Khakass, Khanty, Kikuyu, Kirghiz, Koryak, Kpelle, Kumyk, Kurdish, Lak, Latin, Lezgi, Luba, Macedonian, Malagasy, Malay, Malinke, Maltese, Mansy, Maori, Mari, Maya, Miao, Minangkabau, Mohawk, Moldavian, Mongol, Mordvin, Nahuatl, Nenets, Nivkh, Nogay, Nyanja, Ojibway, Ossetian, Papiamento, Provencal, Quechua, Rhaeto-Romanic, Romany, Rundi, Russian (old spelling), Rwanda, Sami (Lappish), Samoan, Scottish Gaelic, Selkup, Serbian (Cyrillic), Serbian (Latin), Shona, Somali, Sorbian, Sotho, Sunda, Swahili, Swazi, Tabasaran, Tagalog, Tahitian, Tajik, Turkmen (Latin), Tok Pisin, Tongan, Tswana, Tun, Turkmen, Tuvinian, Udmurt, Uigur (Cyrillic), Uigur (Latin), Uzbek (Cyrillic), Uzbek (Latin), Vietnamese, Welsh, Wolof, Xhosa, Yakut, Zapotec, Zulu.
-
-
Artificial languages
-
Esperanto, Interlingua, Ido, and Occidental.
-
-
Programming languages
-
Basic, C/C++, COBOL, Fortran, JAVA, and Pascal.
-
-
Simple chemical formulas
-
Mathematical formulas
-
Digits
Scan separation processing step
Enable this processing step to split a batch scan into multiple documents.
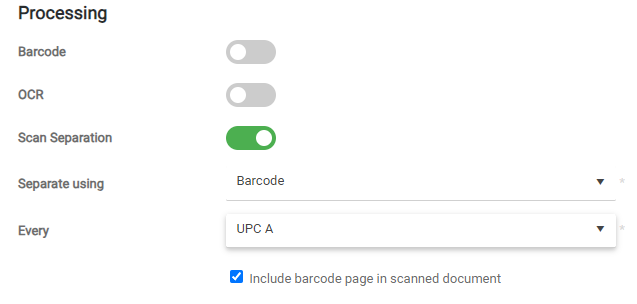
You can separate the scan using the following options:
-
Page count – A new document starts after the number of specified pages. The number of specified pages can be a number or a variable.
-
Barcode – A new document starts when a barcode of the specified type is detected in the scan. The value of the corresponding barcode is stored in the {{separationBarcode}} variable. Pages with these barcodes are included in the scan jobs by default. You can disable this by leaving the Include barcode page in scanned document option blank.
Barcode types:-
UPC A
-
UPC E
-
EAN 8
-
EAN 13
-
Code 39
-
Code 93
-
Code 128
-
Codabar
-
ITF
-
RSS 14
-
RSS Expanded
-
Any 1D barcode
-
Aztec
-
Data Matrix
-
Maxicode
-
PDF 417
-
QR Code
-
-
Standard separation sheet – A new document starts when the standard separation sheet is detected in the scan. You can download the standard separation sheet in the Scan Separation processing step section upon selecting this type of scan separation.
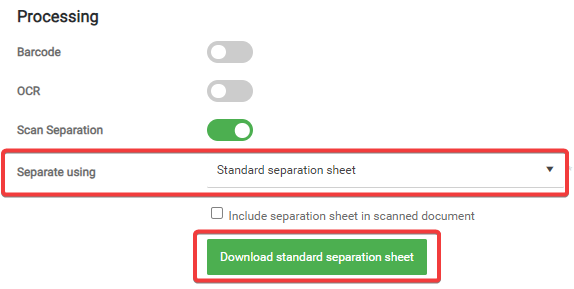
By default, the standard separation sheet is not included in the scan job. You can enable this by selecting the Include separation sheet in scanned document option.
Highlighter redaction processing step
Use the highlighter redaction step to enable the end users to redact areas in a scanned document. The users only need to highlight these areas with a highlighter. In the scanned document, these will be overlaid with black.
The highlighter redaction works in black and white documents only.
Do not combine multiple highlighter colors in one document.
Avoid using orange highlighters.
-
Enable Highlighted text redaction.
-
Select the Highlighter color. Areas highlighted with this color will be redacted.
-
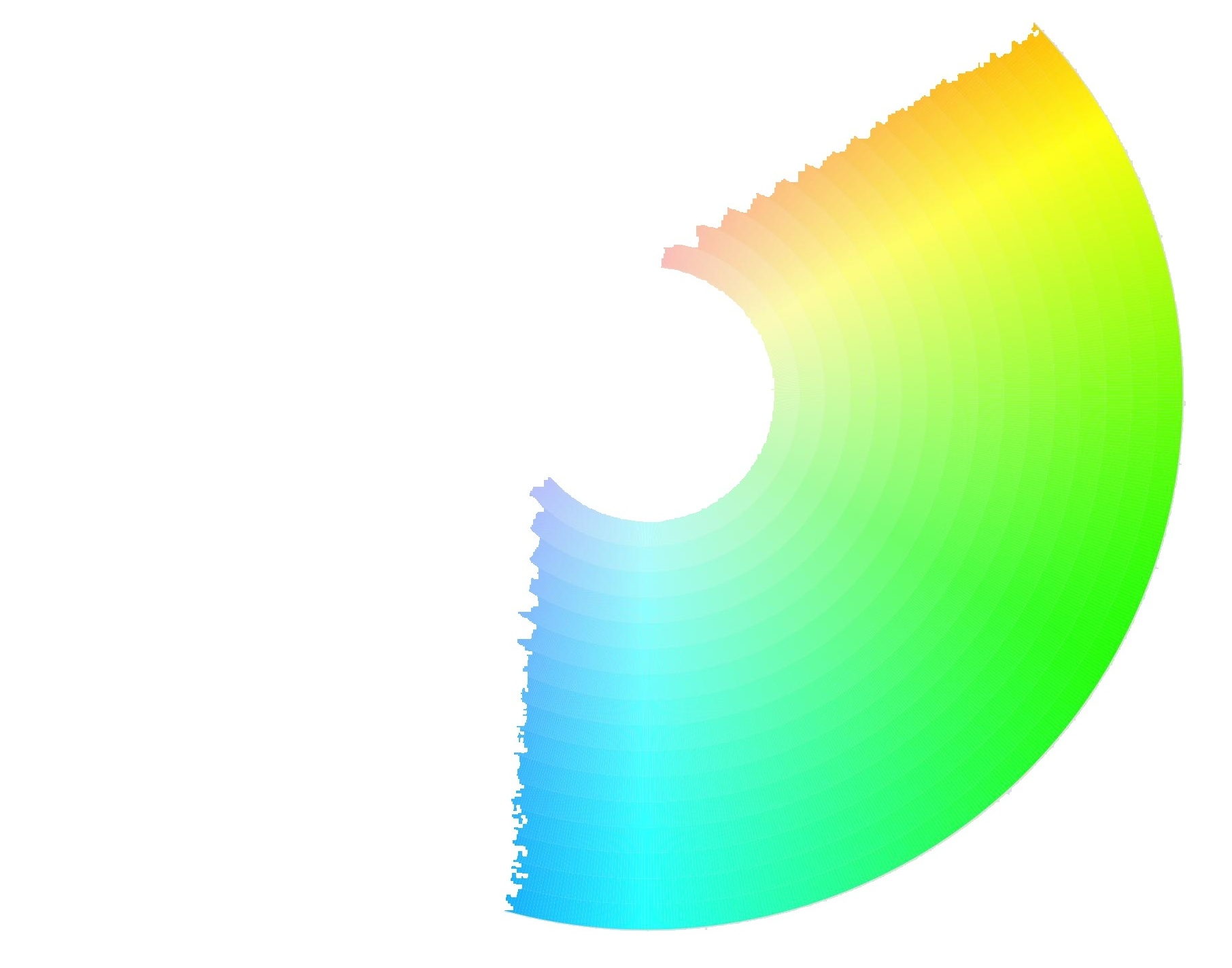
Green – The algorithm can detect the following color range (approximately).
-
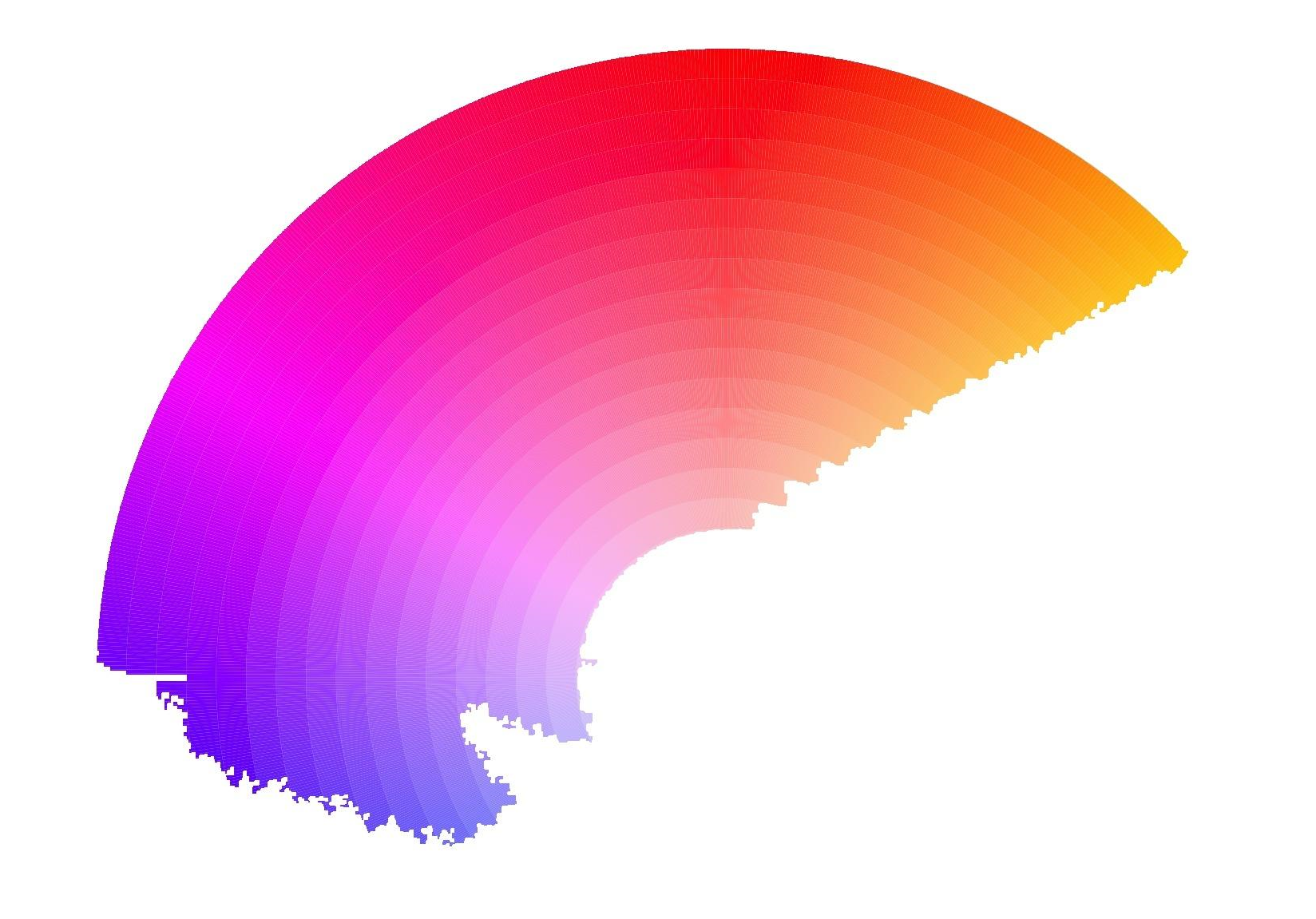
Red – The algorithm can detect the following color range (approximately).
-
-
In Search for highlighter, select whether to search in the whole document or in a range of pages.
-
From – The lower limit of the page range. If empty, the range starts on the first scanned page.
-
To – The upper limit of the page range. If empty, the range ends on the last scanned page.
-
Recommendations
-
The optimal resolution for highlighter redaction is 300 DPI. Higher DPI settings may have a negative impact on the performance.
-
Use the lowest compression settings on MFD. Redaction in highly compressed files is not recommended. Make sure you adjust your MFD settings before redacting.
How to highlight the text correctly
-
Avoid using an orange highlighter. It is on the border between green and red (see the above highlight ranges), therefore the algorithm is unable to process it.
-
Use lighter shades of highlighter. Dark colors might make the text unrecognizable.
-
Make sure that the highlight covers the whole word or region you need to redact in the text.
-
Example of correct usage:

-
Examples of incorrect usage:


-
-
Avoid unequal highlighting. Example:
